

 Курсовая работа: Проектирование компилятора
Курсовая работа: Проектирование компилятора
Курсовая работа: Проектирование компилятора
Министерство образования Российской Федерации.
Федеральное государственное общеобразовательное учреждение высшего профессионального образования
«Чувашский государственный университет имени И.Н. Ульянова»
Алатырский филиал
Курсовая работа
По предмету: «Теория вычислительных процессов и структур»
На тему: «Проектирование компилятора»
Выполнил студент
группы АФТ 61-05
Федин А. В.
Научный руководитель:
Пичугин В.Н.
Алатырь 2009
Задание вариант №9
компилятор идентификатор лексический анализатор


Задание №2
Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, шестнадцатеричных чисел, знака присваивания (:=), знаков операций +, -, *, / и круглых скобок.
Содержание
Введение
1 Организация таблиц идентификаторов
1.1 Назначение таблиц идентификаторов
1.2 Принципы организации таблиц идентификаторов
1.3 Простейшие методы построения таблиц идентификаторов
1.4 Метод простого рехэширования с помощью произведения
2 Проектирование лексического анализатора
2.1 Назначение лексического анализатора
2.2 Таблица лексем и содержащаяся в ней информации
2.3 Построение лексических анализаторов (сканеров)
Заключение
Список использованной литературы
Приложение 1
Приложение 2
Приложение 3
Введение
Компилятор – программный модуль, задачей которого является перевод программы, написанной на одном из языков программирования (исходный язык) в программу на язык ассемблера или язык машинных команд.
Большинство компиляторов переводят программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен компьютером.
Целью данной курсовой работы является изучение составных частей, основных принципов построения и функционирования компиляторов, практическое освоение методов построения составных частей компилятора для заданного входного языка.
Курсовая работа заключается в создании отдельных частей компилятора заданного языка.
В первой части работы ставится задача разработать программу, которая получает на входе набор идентификаторов, организует таблицу по заданному методу и позволяет осуществить многократный поиск идентификатора в этой таблице. Программа должна сообщать среднее число коллизий и среднее количество сравнений, выполняемых для поиска идентификатора.
Во второй части работы требуется разработать программу, которая выполняет лексический анализ входного текста по заданной грамматике и порождает таблицу лексем с указанием их типов и значений.
1 Организация таблиц идентификаторов
1.1 Назначение таблиц идентификаторов
При выполнении семантического анализа, генерации кода и оптимизации результирующей программы компилятор должен оперировать характеристиками основных элементов исходной программы - переменных, констант, функций и других лексических единиц входного языка. Эти характеристики могут быть получены компилятором на этапе синтаксического анализа входной программы (чаще всего при анализе структуры блоков описаний переменных и констант), а также дополнены на этапе подготовки к генерации кода (например при распределении памяти).
Набор характеристик, соответствующий каждому элементу исходной программы, зависит от типа этого элемента, от его смысла (семантики) и, соответственно, от той роли, которую он исполняет в исходной и результирующей программах. В каждом конкретном случае этот набор характеристик может быть свой в зависимости от синтаксиса и семантики входного языка, от архитектуры целевой вычислительной системы и от структуры компилятора. Но есть типовые характеристики, которые чаще всего присущи тем или иным элементам исходной программы. Например для переменной - это ее тип и адрес ячейки памяти, для константы - ее значение, для функции - количество и типы формальных аргументов, тип возвращаемого результата, адрес вызова кода функции.
Главной характеристикой любого элемента исходной программы является его имя. Именно с именами переменных, констант, функций и других элементов входного языка оперирует разработчик программы - поэтому и компилятор должен уметь анализировать эти элементы по их именам.
Имя каждого элемента должно быть уникальным. Многие современные языки программирования допускают совпадения (неуникальность) имен переменных, и функций в зависимости от их области видимости и других условий исходной программы.
Таким образом, задача компилятора заключается в том, чтобы хранить некоторую информацию, связанную с каждым элементом исходной программы, и иметь доступ к этой информации по имени элемента. Для решения этой задачи компилятор организует специальные хранилища данных, называемые таблицами идентификаторов, или таблицами символов. Таблица идентификаторов состоит из набора полей данных (записей), каждое из которых может соответствовать одному элементу исходной программы. Запись содержит всю необходимую компилятору информацию о данном элементе и может пополняться по мере работы компилятора. Количество записей зависит от способа организации таблицы идентификаторов, но в любом случае их не может быть меньше, чем элементов в исходной программе. В принципе, компилятор может работать не с одной, а с несколькими таблицами идентификаторов - их количество и структура зависят от реализации компилятора.
1.2 Принципы организации таблиц идентификаторов
Компилятор пополняет записи в таблице идентификаторов по мере анализа исходной программы и обнаружения в ней новых элементов, требующих размещения в таблице. Поиск информации в таблице выполняется всякий раз, когда компилятору необходимы сведения о том или ином элементе программы. Причем следует заметить, что поиск элемента в таблице будет выполняться компилятором существенно чаще, чем помещение в нее новых элементов. Так происходит потому, что описания новых элементов в исходной программе, как правило, встречаются гораздо реже, чем эти элементы используются. Кроме того, каждому добавлению элемента в таблицу идентификаторов в любом случае будет предшествовать операция поиска - чтобы убедиться, что такого элемента в таблице нет.
На каждую операцию поиска элемента в таблице компилятор будет затрачивать время, и поскольку количество элементов в исходной программе велико (от единиц до сотен тысяч в зависимости от объема программы), это время будет существенно влиять на общее время компиляции. Поэтому таблицы идентификаторов должны быть организованы таким образом, чтобы компилятор имел возможность максимально быстро выполнять поиск нужной ему записи таблицы по имени элемента, с которым связана эта запись.
Можно выделить следующие способы организации таблиц идентификаторов:
□ простые и упорядоченные списки;
□ бинарное дерево;
□ хэш - адресация с рехэшированием;
□ хэш - адресация по методу цепочек;
□ комбинация хэш - адресации ее списком или бинарным деревом.
Далее будет дано краткое описание способа организации таблиц идентификаторов при помощи простого списка.
1.3 Простейшие методы построения таблиц идентификаторов
В простейшем случае таблица идентификаторов представляет собой линейный неупорядоченный список, или массив, каждая ячейка которого содержит данные о соответствующем элементе таблицы. Размещение новых элементов в такой таблице выполняется путем записи информации в очередную ячейку массива или списка по мере обнаружения новых элементов в исходной программе.
Поиск нужного элемента в таблице будет в этом случае выполняться путём последовательного перебора всех элементов и сравнения их имени с именем искомого элемента, пока не будет найден элемент с таким же именем. Тогда если за единицу времени принять время, затрачиваемое компилятором на сравнение двух строк (в современных вычислительных системах такое сравнение чаще всего выполняется одной командой), то для таблицы, содержащей N элементов, в среднем будет выполнено N/2 сравнений.
Время, требуемое на добавление нового элемента в таблицу (Тд), не зависит от числа элементов в таблице (N). Но если N велико, то поиск потребует значительных затрат времени. Время поиска (Ти) в такой таблице можно оценить как Ти = O(N). Поскольку именно поиск в таблице идентификаторов является наиболее часто выполняемой компилятором операцией, такой способ организации таблиц идентификаторов является неэффективным. Он применим только для самых простых компиляторов, работающих с небольшими программами.
Поиск может быть выполнен более эффективно, если элементы таблицы отсортированы (упорядочены) естественным образом. Поскольку поиск осуществляется по имени, наиболее естественным решением будет расположить элементы таблицы в прямом или обратном алфавитном порядке. Эффективным методом поиска в упорядоченном списке из N элементов является бинарный, или логарифмический; поиск.
Алгоритм логарифмического поиска заключается в следующем: искомый символ сравнивается с элементом (N+ 1)/2 в середине таблицы; если этот элемент не является искомым, то мы должны просмотреть только блок элементов, пронумерованных от 1 до (N+ 1)/2 - 1, или блок элементов от (N+ 1)/2 + 1 до N в зависимости от того, меньше или больше искомый элемент того, с которым его сравнили. Затем процесс повторяется над нужным блоком в два раза меньшего размера. Так продолжается до тех пор, пока либо искомый элемент не будет найден, либо алгоритм не дойдет до очередного блока, содержащего один или два элемента (с которыми можно выполнить прямое сравнение искомого элемента).
Так как на каждом шаге число элементов, которые могут содержать искомый элемент, сокращается в два раза, максимальное число сравнений равно 1 + log2 N. Тогда время поиска элемента в таблице идентификаторов можно оценить как Тп = O(log2 N). Для сравнения: при N=128 бинарный поиск требует самое большее 8 сравнений, а поиск в неупорядоченной таблице — в среднем 64 сравнения. Метод называют «бинарным поиском», поскольку на каждом шаге объем рассматриваемой информации сокращается в два раза, а «логарифмическим» — поскольку время, затрачиваемое на поиск нужного элемента в массиве, имеет логарифмическую зависимость от общего количества элементов в нем.
Недостатком логарифмического поиска является требование упорядочивания таблицы идентификаторов. Так как массив информации, в котором выполняется поиск, должен быть упорядочен, время его заполнения уже будет зависеть от числа элементов в массиве. Таблица идентификаторов зачастую просматривается компилятором еще до того, как она заполнена, поэтому требуется, чтобы условие упорядоченности выполнялось на всех этапах обращения к ней. Следовательно, для построения такой таблицы можно пользоваться только алгоритмом прямого упорядоченного включения элементов.
Если пользоваться стандартными алгоритмами, применяемыми для организации упорядоченных массивов данных, то среднее время, необходимое на помещение всех элементов в таблицу, можно оценить следующим образом:
Тд = O(N*log2 N) + k*O(N^2).
Здесь k - некоторый коэффициент, отражающий соотношение между временами, затрачиваемыми компьютером на выполнение операции сравнения и операции переноса данных.
При организации логарифмического поиска в таблице идентификаторов обеспечивается существенное сокращение времени поиска нужного элемента за счет увеличения времени на помещение нового элемента в таблицу. Поскольку добавление новых элементов в таблицу идентификаторов происходит существенно реже, чем обращение к ним, этот метод следует признать более эффективным, чем метод организации неупорядоченной таблицы. Однако в реальных компиляторах этот метод непосредственно также не используется, поскольку существуют более эффективные методы.
1.4 Метод простого рехэширования с помощью произведения.
Для организации таблицы идентификаторов по
методу рехэширования с помощью произведения необходимо определить все
хэш-функции ![]() для
всех
для
всех ![]() Чаще
всего функции
Чаще
всего функции ![]() определяют как некоторую
модификацию хэш-функции h. Например, самым простым методом вычисления функции
определяют как некоторую
модификацию хэш-функции h. Например, самым простым методом вычисления функции ![]() является ее
организация в виде
является ее
организация в виде
![]()
где ![]() — некоторое вычисляемое целое
число, а
— некоторое вычисляемое целое
число, а ![]() —
максимальное значение из области значений хэш-функции h. В данной
работе положим
—
максимальное значение из области значений хэш-функции h. В данной
работе положим ![]() . Тогда получаем формулу
. Тогда получаем формулу
![]()
В этом случае при совпадении значений
хэш-функции для каких-либо элементов поиск свободной ячейки в таблице
начинается последовательно от текущей позиции, заданной хэш-функцией ![]() .
.
Блок-схема метода простого рехэширования представлена на рисунке 1.1.
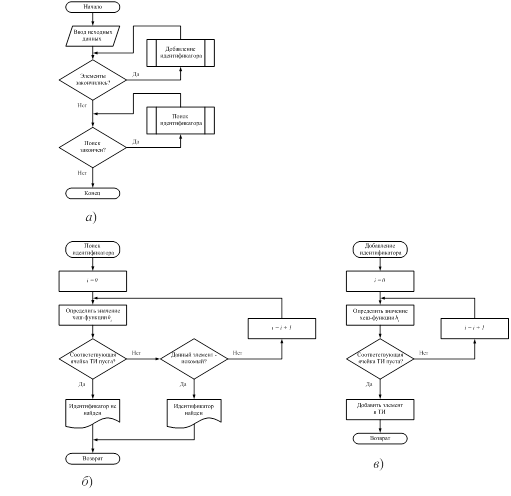
Рис. 1.1 – Блок-схема метода простого рехэширования с помощью произведения
а) – Блок-схема алгоритма простого рехэширования с помощью произведения; б) – Блок-схема функции поиска идентификатора;
в) – Блок-схема функции добавления идентификатора
2 Проектирование лексического анализатора
2.1 Назначение лексического анализатора
Лексический анализатор (или сканер) – это часть-компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
Лексема (лексическая единица языка) – это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п. Состав возможных лексем каждого конкретного языка программирования определяется синтаксисом этого языка.
С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Его функции могут выполняться на этапе синтаксического анализа. Однако существует несколько причин, исходя из которых в состав практически всех компиляторов включают лексический анализ.
Это следующие причины:
- упрощается работа с текстом исходной программы на этапе синтаксического разбора и сокращается объем обрабатываемой информации, так как лексический анализатор структурирует поступающий на вход исходный текст программы и удаляет всю незначащую информацию;
- для выделения в тексте и разбора лексем возможно применять простую, эффективную и хорошо проработанную теоретически технику анализа, в то время как на этапе синтаксического анализа конструкций исходного языка используются достаточно сложные алгоритмы разбора;
- лексический анализатор отделяет сложный по конструкции синтаксический анализатор от работы непосредственно с текстом исходной программы, структура которого может варьироваться в зависимости от версии входного языка - при такой конструкции компилятора при переходе от одной версии языка к другой достаточно только перестроить относительно простой лексический анализатор.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, знаков операций, разделителей и ключевых (служебных) слов входного языка.
Страницы: 1, 2
