

 Реферат: Модель колективного вибору
Реферат: Модель колективного вибору
Результати цих правил голосування можуть сильно відрізнятися за властивостями. Однією із таких властивостей є аксіома монотонності. Правило голосування називається монотонним, якщо кандидат залишається обраним при посиленні його підтримки (тобто коли відносна позиція даного кандидата у чиїхось перевагах поліпшується, а відносні позиції інших кандидатів не змінюються). Всі методи підрахунку очок є монотонними, але деякі відомі методи, що виникають із підрахунку очок, не є такими. Прикладами таких правил служать дуже популярне правило відносної більшості з вибуванням і метод альтернативних голосів.
Є дві аксіоми, що призводять до критики заможних за Кондорсе правил (оскільки дані правила порушують ці аксіоми). З іншого боку, на цих аксіомах заснована характеризація методу підрахунку очок. Ці аксіоми порівнюють кандидатів, обраних різноманітними групами виборців. Вони називаються властивостями поповнення й участі. Поповнення означає, що якщо дві групи виборців , що не перетинаються, (наприклад, сенат і палата представників) обирають того самого кандидата а, то об'єднання цих двох виборчих органів підтвердить обрання а. Участь означає, що виборець не може виграти, утримуючись від голосування, у порівнянні з можливістю брати участь у голосуванні і висловити свої переваги. Будь-яке заможне за Кондорсе правило порушує обидві ці аксіоми. На противагу цьому правила підрахунку очок характеризуються властивістю поповнення (теорема Янга) і задовольняють аксіомі участі. Теорема Янга в даний час є найістотнішим доказом у підтримку методів підрахунку очок, зокрема системи очок Борда.
Заможні за Кондорсе правила голосування усе ж надзвичайно популярні, зокрема, завдяки простоті доведення парного порівняння за правилом більшості. Відповідний клас заможних за Кондорсе методів заснований на послідовних порівняннях за правилом більшості. Законопроект і численні поправки до нього в конгресі США голосуються саме у такий спосіб. Відомий метод послідовного винятку може порушувати умову оптимальності за Парето. Інші методи, засновані на бінарних деревах парних порівнянь за правилом більшості, суперечать аксіомі монотонності. Найпростіше правило, що засноване на послідовному порівнянні і є оптимальним за Парето і монотонним, називається багатоетапним методом винятку. При використанні цього методу потрібно менше парних порівнянь, ніж в інших, концептуально більш простих методах, наприклад у правилі Копленда. За останнім правилом обирається той, хто виграє більшість парних дуелей. Таким чином, голосування, засноване на послідовних парних порівняннях, може задовольняти найбільше важливим аксіоматичним вимогам, але тільки в тому випадку, якщо ми акуратно виберемо цю послідовність.
Правила Борда, відносної більшості та антибільшості являють собою приклади правил голосування з підрахунком очок. Проте правило антибільшості явно не є монотонне, а правило відносної більшості – несправедливе.
Переможець Борда не може бути найгіршим за Кондорсе, так як він є кандидатом, що має найвищий середній бал. За цим правилом завжди знаходяться оптимальний за Парето переможець або їх множина. Прикладами заможних за Кондорсе правил є правила Копленда та Сімпсона. Так само, як і правило Борда або будь-який інший метод підрахунку очок, ці правила вибирають для кожного профілю підмножину переможців, яка може складатись з декількох кандидатів, що одержали однакову оцінку.
Як вже було зазначено, правила голосування повинні бути монотонні, оптимальні за Парето, антонімні і нейтральні. Всі правила голосування з підрахунком очок, крім правила антибільшості, є оптимальні за Парето, монотонні, анонімні і нейтральні, якщо ми не вказуємо, що робити при рівності очок. Крім того, правила голосування повинні задовольняти аксіомі участі та поповнення. Метод Борда відноситься до цих правил (це було показано у попередньому розділі).
Правила Борда і Копленда, як зазначає Мулен, спираючись на практику, не дуже части призводять до рівності очок [1, ст. 299], тому у цьому ракурсі є найкращими. Проте методи Кондорсе, до яких відноситься і правило Копленда, для деяких профілів може не задовольняти аксіомі участі.
Наступною групою правил є правила, засновані на послідовному виключенні за методом підрахунку очок (відносна більшість з вибуванням, метод альтернативних голосів). Проте ці правила, як і будь-які інші методи з вибуванням кандидатів, порушують властивість монотонності для деяких профілів.
Метод рівнобіжного виключення вибирає оптимальний за Парето результат у (найбільше поширеному) випадку, коли при бінарних виборах немає рівностей. Проте якщо рівності можливі, то оптимальність за Парето може порушуватися.
Незважаючи на вище перераховані труднощі, спроможність за Кондорсе, широко відома у якості демократичного принципу, в той час як правило Борда “приховує” справжні симпатії виборців за математичною формулою.
До заможних до Кондорсе правил відносять також наступні методи голосування:
а) голосування з послідовним винятком. За очевидних причин це правило не є нейтральним і оптимальним за Парето, так як порядок виключень впливає на результат голосування. Визначаючи порядок денний, голова фактично контролює процес виборів. Проте це правило досить широко використовується Конгресом США;
б) правило рівнобіжного виключення. Воно породжує дерево без повторних виключень і вимагає проведення цілої низки мажоритарних турнірів. Як було доведено в попередньому розділі, бінарне дерево може дати оптимальне за Парето правило голосування тільки у складнішому випадку, ніж безповторне дерево. Також може порушуватись монотонність;
в) дерево багатоетапних виключень. Цей метод забезпечує проведення наполовину меншої кількості мажоритарних турнірів, ніж метод Копленда. Воно має великий розмір. Кандидатам, можливо, потрібно брати участь у дуелях з тим самим опонентом по декілька разів. Проте його алгоритм є досить простим. Дерево багатоетапного виключення породжує оптимальний за Парето і монотонний метод голосування. Завжди знаходиться єдиний переможець, а не множина. Проте цей метод породжує всі труднощі, які пов’язані з використанням бінарних дерев.
Таким чином, було проведено порівняльну характеристику усіх методів голосування більшістю голосів із виключенням випадків байдужості і подання неправдивої інформації.
Серед заможних за Кондорсе правил голосування ми виявили три методи, що задовольняють основним вимогам оптимальності за Парето, анонімності і монотонності: множина переможців за Коплендом, множина переможців за Сімпсоном і дерево багатоетапного виключення. Серед методів підрахунку очок найкращим виявився метод визначення переможця за Борда. Заможні за Кондорсе правила застосовані на парному порівнянні кандидатів за правилом відносної більшості. Для пересічного виборця вони є найбільш зрозумілими.
Правило Борда задовольняє аксіомі участі та поповнення, але приховує за математичною формулою справжні переваги виборців.
Для програмної реалізації виберемо один з методів Копленда як найпростіший і для порівняння визначимо переможця за Борда.
Приведемо ще раз правила Копленда і Борда для того, щоб перейти до формулювання алгоритму програми.
Правило Борда. Кожний виборець повідомляє свої переваги, ранджуючи р кандидатів від кращого до гіршого (байдужність забороняється). Кандидат не одержує очок за останнє місце, одержує одне очко за передостаннє і так далі, одержує р-1 очок за перше місце. Перемагає кандидат із найбільшою сумою очок. Він називається переможцем за Борда.
Правило Копленда. Порівняємо кандидата а з будь-яким іншим кандидатом х. Нарахуємо йому +1, якщо для більшості а краще за х, -1, якщо для більшості х краще за а, і 0 при рівності. Сумуючи загальну кількість очок по всім х, х¹а, одержуємо оцінку Копленда для а. Обирається кандидат, названий переможцем за Коплендом, із найвищою з таких оцінок.
Вважаємо, що вхідними даними задачі є вже згрупована інформація: сформовані групи виборців з однаковими у кожній групі рангами переваг. Проте допускається і занесення інформації кожним виборцем окремо.
4 Опис алгоритму
У даному розділі наводяться алгоритми для знаходження переможців виборів.
Для визначення переможців Борда та Копленда скористаємося безпосередньо наведеними вище правилами, тобто реалізуємо їх програмно.
Складність алгоритмів, описаних нижче, прямо пропорційна кількості груп виборців та кількості кандидатів, що ще раз підтверджує приналежність даної задачі до Р-типу.
4.1 Визначення переможця Борда
Для знаходження оцінок Борда кандидати ранджуються, тобто за кожне місце у шкалі виборців кандидат отримує певну кількість балів. Далі ці бали сумуються.
Введемо наступні змінні.
Нехай М – кількість кандидатів;
S – кількість груп виборців;
Nаme[M] – масив імен виборців;
Rаng[1..M, 1..S] – профіль переваг;
Many[S] – кількість виборців у кожній групі;
Bord[M] – масив оцінок кандидатів.
Розглядаємо окремо кожну групу виборців. Для цієї групи кандидат отримує оцінку [кількість виборців many[i]]*([кількість кандидатів M] – [поточне значення лічильника j]). Знайдена оцінка додається до попередньої. Алгоритм продовжує роботу до тих пір, поки не будуть розглянуті усі групи виборців (i=S).
За правилом Борда отримуємо наступний алгоритм для знаходження оцінок Борда.
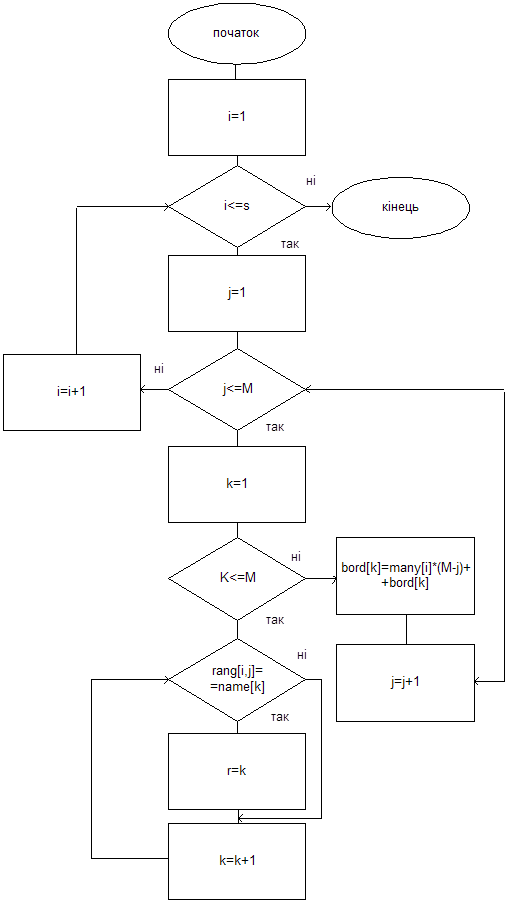
Рис. 4.1 Алгоритм знаходження оцінок Борда
4.2 знаходження оцінки Копленда
Для знаходження оцінки Копленда крім вище наведених використаємо наступні змінні:
Kopl[M] – масив оцінок Копленда;
Vybor1, vybor2 – допоміжні змінні; використовуються для перегляду імен кандидатів з масиву імен name.
Порівняння проходить наступним чином.
Змінній vybor1 присвоюємо значення імені першого кандидата з множини імен name (contrl=1), а vybor2 – наступне (k=contrl+1). Якщо vybor1 знаходиться вище, ніж vybor2, у перевагах виборців усіх груп, то до оцінки Копленда (kopl[contrl]) кандидата vybor1 додається очко, а vybor2 (kopl[k]) – віднімається і навпаки. Далі змінній vybor2 присвоюється наступне значення з масиву імен (k=k+1), і процедура порівняння знову повторюється. Цикл продовжується до тих пір, поки не вичерпаються імена у списку кандидатів.
Після цього змінній vybor1 присвоюється друге ім’я із списку кандидатів (contrl=contrl+1), а vybor2 – третя. Знову проходить цикл по змінній vybor2. Цикл по змінній vybor1 закінчується тоді, коли буде переглянуто усіх кандидатів.
Отримуємо наступний алгоритм знаходження оцінки Копленда.
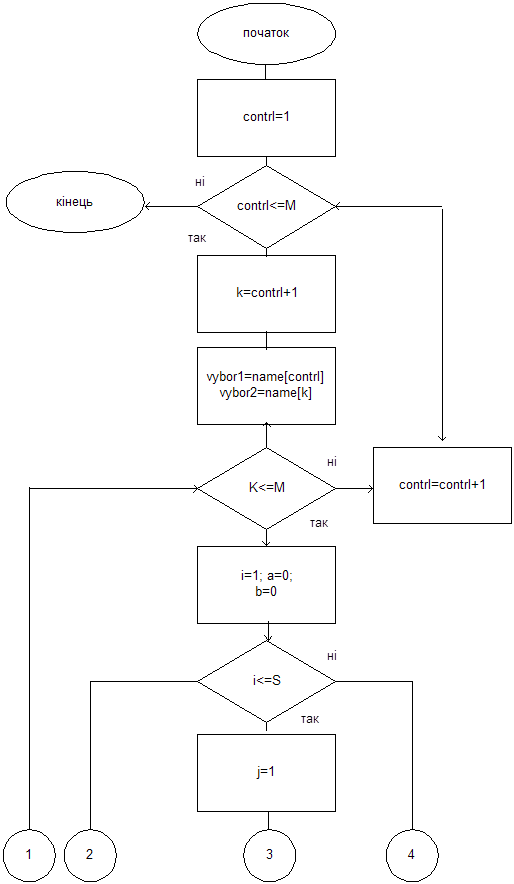
Рис. 4.2 Алгоритм знаходження оцінок Копленда (початок)
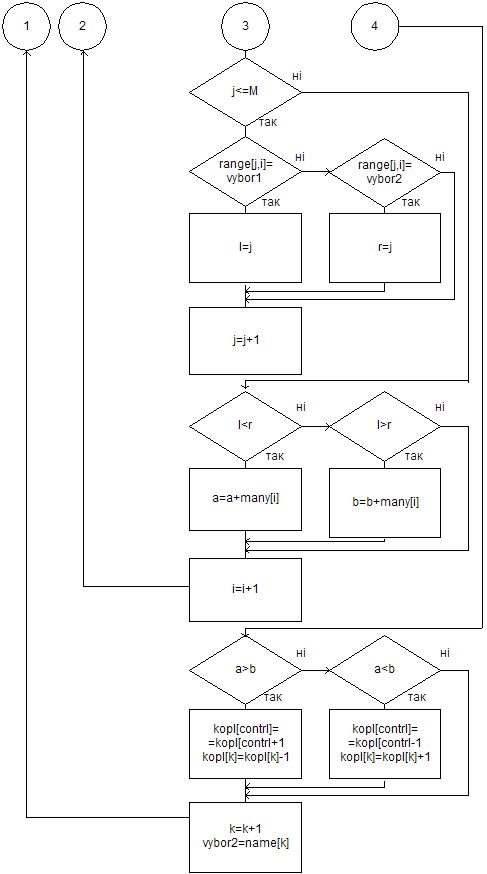
Рис. 4.3 Алгоритм знаходження оцінок Копленда (закінчення)
4.3 Алгоритм визначення переможця за правилами Борда чи Копленда
Як можна було побачити, переможцем за Борда (Коплендом) є кандидат з найвищою сумою очок. Тому процес його визначення є однаковим для обох випадків , і я його об’єднала одним алгоритмом.
Як відомо, правила Копленда і Борда породжують множину розв’язків.
Для знаходження переможця використаємо наступні змінні:
K – кількість переможців;
Max – оцінка переможців;
Hl[M] – масив номерів переможців.
Спочатку масив номерів переможців заповнюємо нулями.
Масиви оцінок Копленда і Борда (kopl i bord) замінимо формальним масивом v[M].
Після того, як ми знайшли оцінки для кандидатів (масиви kopl i bord), серед них шукаємо максимальну (max). Далі відбираємо кандидатів, оцінка яких дорівнює max (їх номери з масиву name заносяться у масив hl), і рахуємо кількість переможців (k).
Переглядаємо заповнений масив hl. Якщо у ньому тільки перше значення є відмінне від нуля, то це означає, що ми знайшли єдиного переможця, і, отже, зберегли умову нейтральності.
В іншому випадку проглядаємо ті значення імен кандидатів (масив name), номери яких зустрічаються у масиві hl. Відібрані імена кандидатів впорядковуємо за списком. Переможцем стає той, ім’я якого знаходиться першим у даному списку.
У даному випадку умова нейтральності не зберігається.
Отже, ми отримали наступний алгоритм.
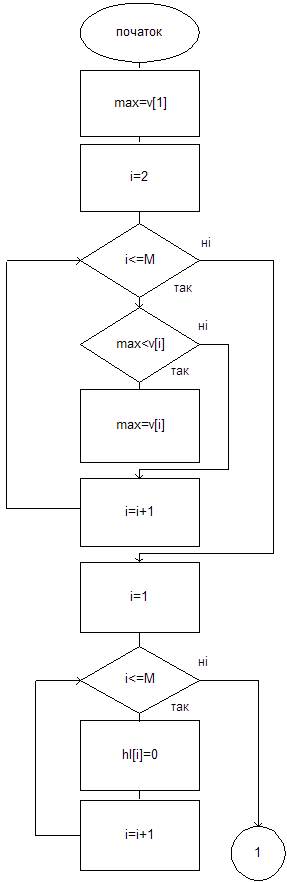
Рис. 4.4 Алгоритм визначення переможця (початок)
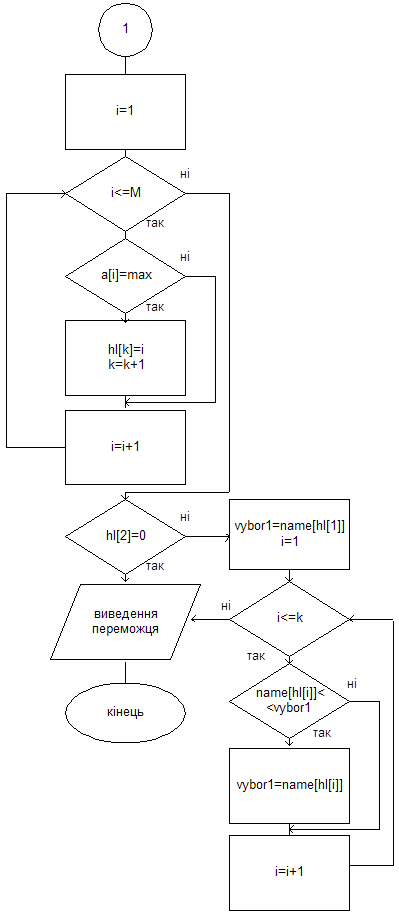
Рис. 4.5. Алгоритм визначення переможця (закінчення)
5 Опис програми
5.1 Вибір технології програмування
Найбільш поширеними парадигмами програмування, які до того ж можуть бути використані у даній курсовій роботі, є парадигми процедурного та об’єктно-орієнтованого програмування.
Парадигма процедурного програмування найбільше широко поширена серед існуючих мов програмування (наприклад, Сі і Паскаль). Тут явно виділяють два види різноманітних сутностей:
1) процедури, що виконують активну роль, тобто являються тим, що задає поведінку (функціонування) програми;
2) дані, що виконують пасивну роль, тобто являють тим, що опрацьовується засобом, продиктованим процедурами. Спроможність складати процедури з команд (операторів) і викликати їх є ключем даної парадигми. Особливістю цієї парадигми є "бічні ефекти", що виникають у тих випадках, коли різноманітні процедури, що використовують загальні дані, незалежно їх змінюють.
У процедурній парадигмі активна роль в організації поведінки приділяється процедурам, а не даним; причому процедура активізується викликом. Подібні засоби завдання поведінки зручні для описів детермінованої послідовності дій або одного процесу, або декількох, але строго взаємозалежних процесів.
При використанні програмування, орієнтованого на дані, активну роль відіграють дані, а не процедури. Тут із структурами активних даних зв'язують деякі дії (процедури), що активізуються тоді, коли здійснюється доступ до цим даним. Деякі спеціалісти називають цей засіб активації дій "демонами". Програмування, орієнтоване на дані, дозволяє організувати поведінку мало залежних процесів, що важко реалізувати в процедурній парадигмі. Мала залежність процесів означає, що вони можуть розглядатися і програмуватися окремо. Проте при використанні парадигми, керованої даними, ці незалежно запрограмовані процеси можуть взаємодіяти між собою без їхньої зміни (тобто без перепрограмування).
Парадигма об'єктного програмування на відміну від процедурної парадигми не розділяє програму на процедури і дані. Тут програма організується навколо сутностей, названих об'єктами, що включають локальні процедури (методи) і локальні дані (змінні). Поведінка (функціонування) у цій парадигмі організується шляхом пересилки повідомлень між об'єктами. Об'єкт, отримавши повідомлення, здійснює його локальну інтепретацію, базуючись на локальних процедурах і даних. Такий підхід дозволяє описувати складні системи найбільш природним чином. Особливо він зручний для інтегрованих ІС.
Об'єктно-орієнтоване програмування (ООП) базується на абстракціях даних. В основі цього методу лежить представлення предметної області у вигляді сукупності об’єктів, які взаємодіють між собою через передачу повідомлень. Модель абстракції даних полягає в інкапсуляції даних та операцій над ними в окремий класовий тип. Доступ до даних можлива лише за допомогою інкапсульованих операцій. Класовий тип є автономно завершеним і дозволяє повне або часткове наслідування для інших класів. ООП концентрується на суті задачі, для якої розробляється програма. Задача будується як сукупність об'єктів, які взаємодіють між собою за допомогою повідомлень. Елементи програми розробляються у відповідності з об'єктами в описі задачі. Суть ООП полягає у визначенні найбільш вдалих об'єктових типів. Об'єктовий тип служить модулем, який може бути використаним для розв'язку інших подібних задач. Такий підхід не потребує спеціальної обчислювальної техніки, але суттєво відрізняється характером мислення виконавців у порівнянні з процедурними мовами програмування.
